
AI Eats Software Testing
Automated Input Diversification (AID) is a Breakthrough in Software Testing

In the fast-paced world of software, squashing bugs is a never-ending battle…
A recent paper introduces a groundbreaking LLM-powered method called AID (Automated Input Diversification), which significantly boosts our ability to detect bugs. Massive implications for software engineering.
Let’s say you have a potentially buggy software program that passes all unit tests written by your engineering team - how do you find new test cases on which the program fails?
AID does exactly that: given a software program, its specification, and a set of passing tests… AID produces a failing test that reveals a bug in the program.
Imagine AID-supercharged CI/CD pipelines, with LLMs proactively uncovering bugs and missed tests. This future is near.
What is AID?
AID stands for Automated Input Diversification, a new approach combining LLMs with differential testing to create robust test cases.
Differential testing works by comparing the outputs of different versions of a program when given the same input. If outputs are different, then there’s a defect in the program.
AID leverages the computational power of LLMs to generate diverse program variants, and then employs differential testing to compare these variants. By examining discrepancies in outputs, AID identifies bugs with stunning accuracy.
How It Works
AID has 3 steps:
Generate program variants
Generate test case generator
Differential testing
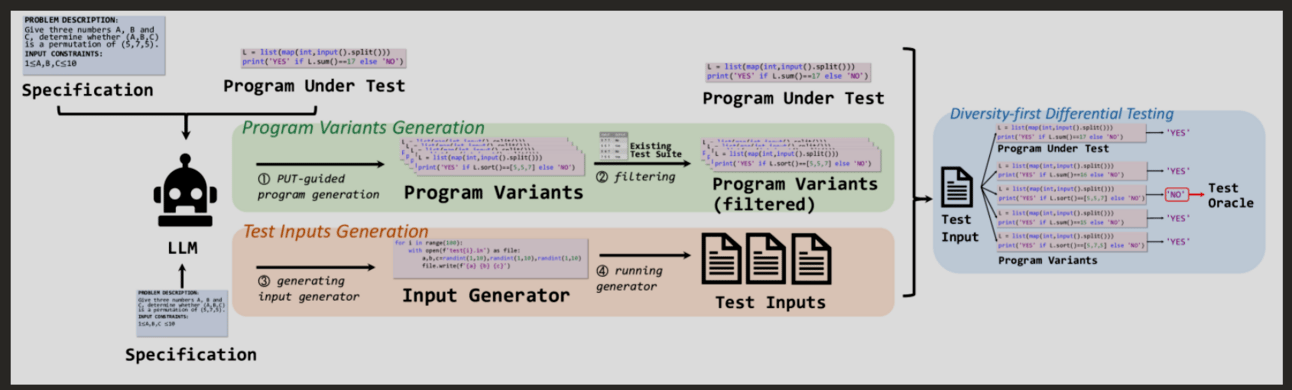
1. Generate Program Variants
Program variants are generated by an LLM — here’s the prompt:
INSTRCUTION:
You are a professional coding competition participant, skilled at identifying bugs and logic flaws in code. You will receive a description of a coding problem, and a piece of code attempting to solve the problem. Your task is to find whether there is any bug or logic flaw in the code, if any, please repair the code. Please reply with ONLY the COMPLETE REPAIRED CODE (rather than code fragments) without any other content.
PROBLEM DESCRIPTION: {The specification of the coding task}
CODE: {Source code of PUT}A problem variant is an attempt to fix broken code. It’s easy to check whether it’s valid (e.g. runs) and passes existing tests - it should, otherwise something is wrong. The original program is part of the training set, and its source is fed as part of the prompt.
2. Generate Test Case Generator
Instead of generating test samples directly, this paper asks LLMs to generate code that generates samples. Pretty meta. It’s an interesting modality shift — LLM is not a generator anymore, a python program is. This is useful for software developers because you can always inspect the output and tweak it. Also, this allows you to improve it by continuously feeding the test generator code into an LLM, asking it to make adjustments.
Here’s the prompt:
**INSTRCUTION**:
The following is a description of a coding problem,
please write an input generator for this problem (DO NOT
generate outputs).
The generated inputs should meet the input constraints of
the problem description.
Please reply with ONLY the code without any other content.
You can use the python library {library name} if
necessary, here are some examples of how to use the
library, which may be helpful:
{Few-shot examples to use the library}
**PROBLEM DESCRIPTION**:
{The specification of the coding task}Try these prompts on some functions from your favorite libraries on github (especially one-off utility functions), and let me know what it produces!
3. Differential Testing
The idea behind differential testing is this:
Given N programs with the same intent (i.e. intent is to solve the problem outlined by the spec)… any discrepancy between the outputs indicates a potential bug. Hence, the name “differential” testing.
AID’s underlying assumption is that program variants will exhibit the same behavior as the original program. Under this assumption, a test case is considered a test oracle (i.e. meaning it reveals a bug) if an output of a variant is different from the output of the plausibly correct program.
Here’s the LLM prompt to generate diverse program variants:
INSTRCUTION:
You are a professional coding competition participant, skilled at identifying bugs and logic flaws in code. You will receive a description of a coding problem, and a piece of code attempting to solve the problem. Your task is to find whether there is any bug or logic flaw in the code, if any, please repair the code. Please reply with ONLY the COMPLETE REPAIRED CODE (rather than code fragments) without any other content.
PROBLEM DESCRIPTION: {The specification of the coding task}
CODE: {Source code of PUT}Does AID Outperform Existing Methods?
The paper evaluated AID against three baseline methods across two major datasets: Trickbugs (C++) and Trickybugs (Python), and a third dataset called EvalPlus. The results were striking:
AID consistently outperformed in terms of precision and recall.
Its worst performance still surpassed the best performance of the next best method, DPP.
Across various metrics, AID showed improvements ranging from 65.57% to 165.11% over competing methods.
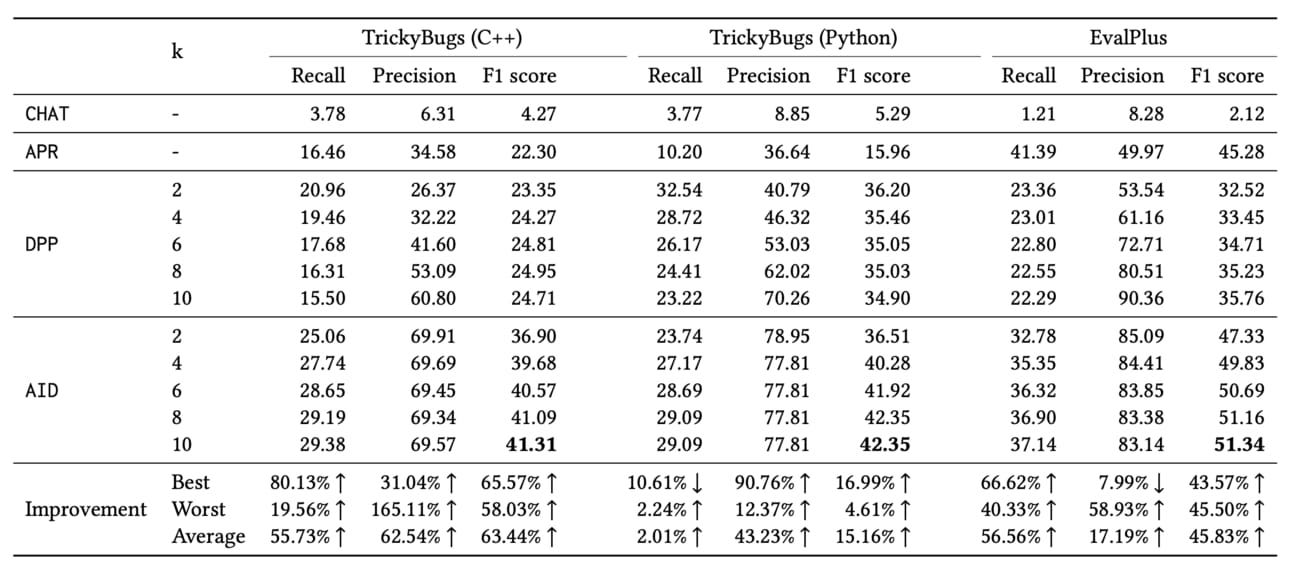
Recall, Precision, and F1 Scores
AID's ability to detect tricky bugs can substantially improve the reliability and safety of software apps, impacting everything from personal devices to critical systems in healthcare and finance.
While AID marks a significant advance, noticeably its recall rate is lower.
This may be because AID prioritizes identifying and accurately pinpointing defects in the code, leading to a higher precision in detecting true positives (i.e., correctly identifying defects). However, this focus on precision may result in lower recall, as AID may miss defects or have a lower sensitivity to identifying all possible defects in the code. Additionally, AID may have been designed to prioritize the reduction of false positives (i.e., incorrectly identifying defects), which would contribute to higher precision. This focus on reducing false positives may lead to a more conservative approach in identifying defects, potentially resulting in lower recall.
Math Interpretation
Every correct program (from a format verification standpoint) is plausibly correct, as it passes tests.
Every program is trivially plausibly correct if the set of unit tests is empty (yes — you can write plausibly correct programs by not writing tests!)
If the input space is not finite, since the set of tests is finite, we cannot determine if a plausibly correct program is indeed correct using tools like AID.
A program under test from a sample in the training data passes all the given unit tests — it can be treated as a lossy reconstruction of the correct program (or a set of all correct programs) with perhaps some measure of how close that program is to the correct program by inducing some metric on the test set.
In some other hand-wavy sense, the trickiest programs to debug are the one that appear “dense” in the test set — they pass an infinite subset of the input space test cases with one off problem points that are not obvious edge cases (e.g. a function that takes a single integer as an input only fails on input 10).
As software developers, we don’t formally prove that a program is correct — though we do try to execute something close to that process, informally, and perhaps even inductively, in our heads, to prove to ourselves that our algorithm is correct.
Now, imagine taking this to the next level: asks LLMs formally verify a program, ensuring it is provably correct. This could be part of the next-gen LLM-powered CI/CD pipeline!
Open Questions
These questions come to mind, as I consider what it will take to migrate AID from research to industry:
How well does AID perform in other programming languages besides C++ and Python?
What specific types of bugs is AID most effective at detecting?
Are there any real-world applications where AID can already be implemented? Are we limited to mostly competition style problems?
What would the integration of AID into existing testing frameworks look like?
What are the computational requirements to run AID effectively in a commercial setting?
How do developers handle the lower recall rate when using AID in critical systems?
Can AID be combined with other testing methods like fuzz testing or formal verification for even better results?
Need More Help? 👋
1/ If you want to grow on social media and scale your business in coaching, consulting, speaking, selling apps, or digital products… check out Blotato
2/ Free AI courses & playbooks here
3/ Free AI prompts & AI automations